중국어로 이루어진 텍스트를 만드는 데까지는 일사천리로 이루었으되, 이것을 그냥 두면 '꿰지 않은 구슬'일 뿐이오.
널리 이용하는 '한글'을 통해 '꿰인 구슬'로 만들어 보쇠다.
그대로 편집하면 되지만, 간체자가 부담스러워 번체자로 바꾸고 싶다면, 아래와 같이 하면 되오.
* * *
비록 문자인식이라는 기술이 참으로 좋기는 하나, 아직은 100%의 인식률을 보이지는 않소.
인식률이 99%라 하여도 한 페이지당 3~5 글자 정도는 오식되는 셈이니, 오식을 찾아 고쳐주는 것도 보통 일은 아니오.
그리고, '한글'에서도 간혹 코드가 맞아떨어지지 않는 경우가 있어 엉뚱한 글자로 바뀔 수 있으니, 면밀히 교정하는 작업이 필수적이라 하겠소.
* * *
이상으로 SH OCR 6.0을 이용한 문자인식에 대하여 알아보았소.
지금은 8.0이나 10.0 버전이 나왔을지도 모를 일이구료. 언젠가 구해지면 또 다루어보리다.
널리 이용하는 '한글'을 통해 '꿰인 구슬'로 만들어 보쇠다.
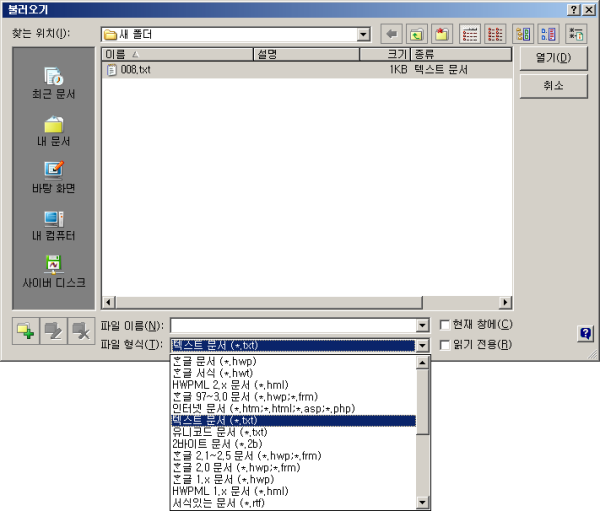
'한글'을 실행하여 '불러오기'를 하오.<br />'파일 형식'을 '텍스트 문서' 또는 '유니코드 문서'로 선택하여 열어야 하오.
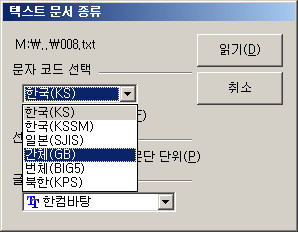
'문자 코드 선택'을 '간체(GB)'로 하고 '읽기'를 클릭하오.
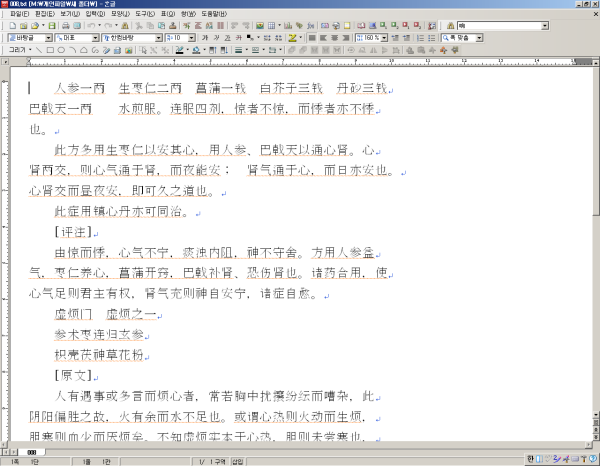
이렇게 매끈하게 읽어지게 되오.<br />한글 200x은 물론이고, 한글 97에서도 잘 읽히오.
그대로 편집하면 되지만, 간체자가 부담스러워 번체자로 바꾸고 싶다면, 아래와 같이 하면 되오.
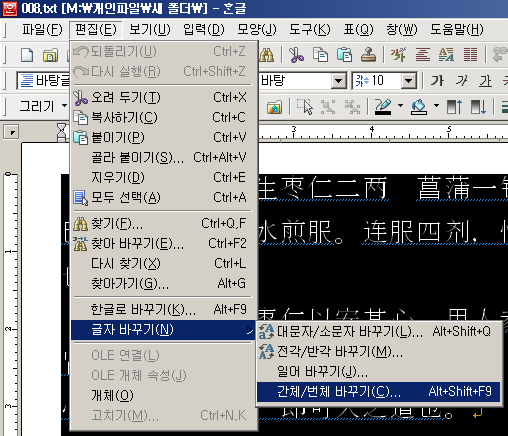
먼저 전체선택을 하고(단축키 [Ctrl+A]),
메뉴의 '편집'에서 '글자 바꾸기'→'간체/번체 바꾸기'를 클릭하오.<br />단축키는 [Alt+Shift+F9] 되겠소
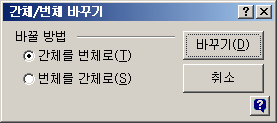
간체/번체 바꾸기 창이 뜨면 '바꿀 방법'에서 '간체를 번체로'를 선택하고 [바꾸기]를 누르오.
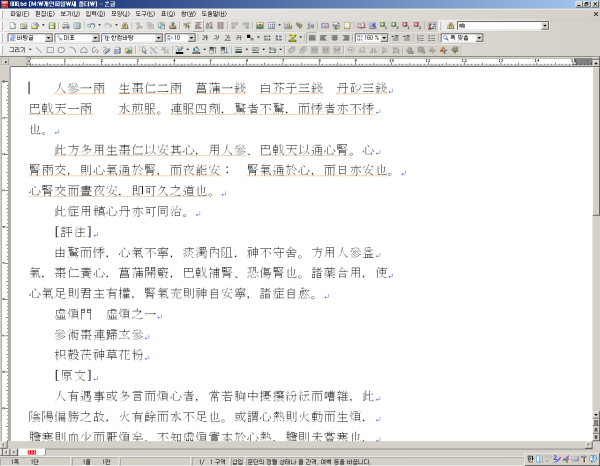
이와 같이 멋스러운 번체자로 모두 바뀌었소.
* * *
비록 문자인식이라는 기술이 참으로 좋기는 하나, 아직은 100%의 인식률을 보이지는 않소.
인식률이 99%라 하여도 한 페이지당 3~5 글자 정도는 오식되는 셈이니, 오식을 찾아 고쳐주는 것도 보통 일은 아니오.
그리고, '한글'에서도 간혹 코드가 맞아떨어지지 않는 경우가 있어 엉뚱한 글자로 바뀔 수 있으니, 면밀히 교정하는 작업이 필수적이라 하겠소.
* * *
이상으로 SH OCR 6.0을 이용한 문자인식에 대하여 알아보았소.
지금은 8.0이나 10.0 버전이 나왔을지도 모를 일이구료. 언젠가 구해지면 또 다루어보리다.
'~하는 법' 카테고리의 다른 글
| PDF 변환 프리웨어 'PDF Creator' 사용법 1. 설치 (2) | 2007.11.19 |
|---|---|
| SH OCR 6.0 (2. 문자인식) (0) | 2006.03.25 |
| SH OCR 6.0 (1. 설치) (1) | 2006.03.25 |



